분류 결과표(Confusion Matrix)
분류 문제에서 성능을 측정하는 방법은 여러가지인데, 그 중 Confusion Matrix란, 타겟의 원래 클래스와 모형이 예측한 클래스가 일치하는지 갯수로 센 결과를 표로 나타낸 것이다.
이진 결과표의 경우 (Binary Confusion Matrix)
| 양성이라고 예측 | 음성이라고 예측 | |
| 실제 양성 | 양성 예측이 맞음 (True Posivite) |
음성 예측이 틀림 (False Negative) 제 2종 오류 |
| 실제 음성 | 양성 예측이 틀림 (False Positive) 제 1종 오류 |
음성 예측이 맞음 (True Negative) |
다양한 평가점수
정확도 : 전체 샘플 중 맞게 예측한 샘플 수의 비율 (accuracy)
정밀도 : 양성 클래스에 속한다고 에측한 것 중 실제로 양성 클래스에 속하는 샘플 수의 비율 (precision)
재현율 : 양성 클래스에 속하는 표본 중에, 양성이라고 예측한 샘플 수의 비율 (recall)
위양성율 : 음성 클래스에 속하는 표본 중에, 양성이라고 예측한 샘플 수의 비율 (fallout)
F점수 : 정밀도와 재현율의 가중조화 평균, 특별히 일반 조화평균일 경우, F1점수
y_true = [0, 0, 1, 1, 2, 2, 2]
y_pred = [0, 0, 1, 2, 2, 2, 1]
target_names = ['class 0', 'class 1', 'class 2']
print(classification_report(y_true, y_pred, target_names=target_names))ROC 커브와 AUC
좋은 분류를 질병 예측 상황에 써보자.
- 모든 환자에게는 양성 판단을 내려야 할 것이다.
- 모든 정상인에게는 음성 판단을 내려야 할 것이다.
즉, 만일 모든 진단에 양성을 내린다면? 정상인이 모두 다 환자로 판정받는다. FP/(FP+TN) = 1로 치솟아오른다.
만일 모든 진단에 음성을 내린다면? 환자들은 환자가 될 수 없다. TP/(TP+FN) = 0으로 떡락된다.
여기서 우리는 True Positive Rate, False Positive Rate 2가지를 고려할 수 있다.
TPR = TP / (TP + FN) -> 진짜 양성 비율, 양성 환자를 올바르게 양성이라고 말할 확률
FPR = FP / (FP + TN) -> 거짓 양성 비율, 음성 환자를 올바르지 않게 양성이라고 말할 확률.
즉, 완벽한 분류는 TPR은 1, FPR은 0인 것이다.
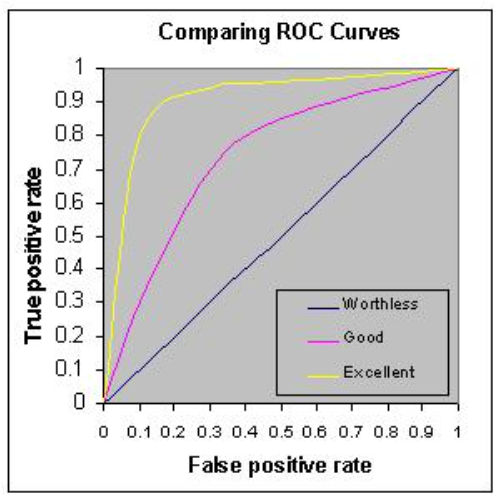
무작위로 분류할 경우, 클래스별로 오차율이 비슷해져, FPR = TPR이 된다. 따라서 기울기가 1인 경우는 무의미하고, 직선에서 멀어질수록, 더 좋은 분류다., 여기서 ROC 커브의 밑면적을 AUC라 한다.
'Archive > 데이터 분석 관련' 카테고리의 다른 글
| [Data] 분류 알고리즘 - Decision Tree, Random Forest (0) | 2021.06.01 |
|---|---|
| [Data] 로지스틱 회귀분석 (0) | 2021.06.01 |
| [Data] Scikit-learn을 통한 Pipeline 구축 (0) | 2021.06.01 |
| [Data] p-value Revisited, p-hacking이란? (0) | 2021.05.27 |
| [DS] 주성분 분석, PCA (0) | 2021.04.27 |



