* 풀잎스쿨 사전학습을 위한, 이론 파악.
* 각각에 대한 자세한 내용 보다도, 개괄적으로 어떤 부분이 이것을 만들었고 주요 모델의 특징에 대해 이해하고자 한다.
NLP에서의 희소문제
등장 확률을 기반으로 하는, 통계적 언어 모델에서 만일 특정 단어나 어구가 corpus에 등장하지 않는다면, 그 확률은 당연히 0이 될 것이다.
문제는 수치적 확률은 0인데, 존재할 법한 단어나 문장이라면? 예측 성능에 문제가 될 것이다. 이에 대한 해결책에 대해 고민해야 할 것이다. 이를 개선할 수 있는 방법을 고려해보려고 한다.
N-gram
N-gram도 횟수를 사용하여 단어를 표현하는 방법이다. N-gram은 한 단어 이상의 단어 시퀀스를 분석 대상으로 삼게 된다.
Ex) This is a sentence면 2-gram은 (This is),(is a), (a sentence) 이런 식.
N-gram이 희소성을 해결해줄 수 있는 이유는, 2단어 이상의 묶음을 학습하면, 특정 단어 뒤에 올 단어의 경우의 수가 증가하게 되는 장점이 있다.
N-gram의 단점 : 장기 의존성 문제
N-gram의 가장 큰 문제는, 일부 단어 시퀀스만을 가지고 판단하기에 문장 앞 쪽의 문맥을 파악하지 못한다는 단점을 가진다. 즉, 횟수만 가지고 판단하기에 실제로는 문맥에 더 어색한 단어여도 등장 빈도가 더 높다는 이유로 채택될 가능성이 높아진다. 즉, 문맥을 어떻게 고려할 것인지에 대해 고민해야 하는 문제가 발생한다. N-gram에서는 이를 해결하기 위해 N을 1~5 정도를 섞어서 활용하게 된다.
Word2Vec이란
Word2Vec은 2개의 Hidden Layer를 가지고 있는 얕은 신경망으로 단어를 표현하게 된다.
Word2Vec은 기본적으로 "비슷한 위치에 등장하는 단어들은, 비슷한 의미를 가진다"라는 가정에서 출발한다.
즉, 주변 단어들을 바탕으로 목표 단어를 예측 하는 문제를 고려하게 되는 것이다.
Word2Vec의 두 가지 방식
두 가지 방식은 다음과 같다.
(1) CBOW : 주변의 단어로 중간의 단어를 추정
(2) Skip-gram : 중간의 단어로 주변 단어를 추정
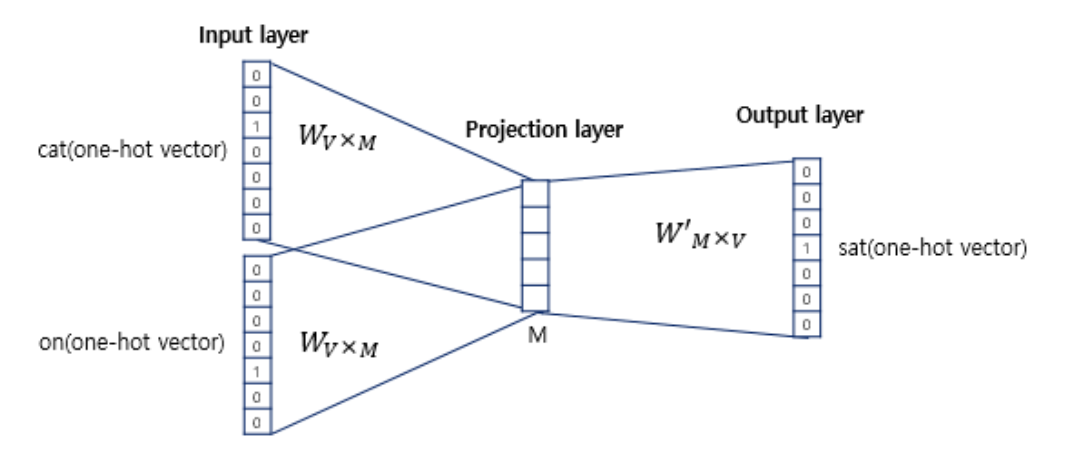
CBOW의 경우는 다음과 같이, 주어진 주변 단어들별로, 가중치 행렬을 추정하여 평균을 구하며 한번의 projection을 시키고, 이의 결과를 다시 최종 단어 추정 학습에 활용한다.

skip-gram의 경우에는, 반대로 중심 단어로 주변 단어를 예측한다. 즉, projection 과정에서 평균 구하는 과정이 필요없다.
Word2Vec의 단점
(1) 계산량이 압도적으로 크다.
기본적으로 Word2Vec의 입력벡터는 one-hot encoding된 벡터기에, 연산량이 상당히 크다.
-> 이를 극복하기 위해 Negative Sampling이 도입된다.
(2) 결국은 그래도 context를 읽어내기 어렵다. (특히, 동음이의어의 경우!)
Word2Vec은 임베딩 벡터가 윈도우 크기 내에서만 주변 단어를 고려하게 된다. 즉 corpus의 전체적인 통계량을 반영하지 못한다.
Glove란?
Glove(Global Vectors for Word Representation)는 카운트 기반과 예측 기반을 복합적으로 사용하는 방법론이다.
Glove는 무엇을 하고 싶은가?
Glove는 동시 등장 확률에 대해 고려한다. 즉, 학습 말뭉치에서 동시에 등장한 단어의 빈도를 세어, 말뭉치의 단어 개수로 나눠주면 된다.
이렇게, 동시 등장 확률을 계산 후 특정 단어에 대해서 "주어딘 두 단어 벡터의 내적이, 두 단어의 동시 등장 확률"을 나타낼 수 있도록, 벡터를 지정해보려는 것이 Glove가 하려는 짓이다.
https://wikidocs.net/22885
위의 링크에서, 자세한 수식 설명을 확인할 수 있다.
Glove의 수식을 풀기 위한, 핵심은 "두 단어 동시 등장 확률의 크기 관계"를 벡터에 녹여내는 것이 관건이다. 이를 위해 두 입력 단어의 차이와와 주변 단어 벡터를, 동시 등장 확률의 비로 표하게 된다.

중심 단어와 주변 단어의 선택의 교환을 자유롭게 하기 위해 homorphism 조건이 만족되어야 하고, 이를 위한 수식 전개 과정이 상단의 링크에 정리되어 있다.
'Archive > 자연어처리' 카테고리의 다른 글
| [NLP] FastText란? (0) | 2022.04.30 |
|---|---|
| [NLP] ELMo란 무엇일까? (0) | 2022.04.28 |
| [NLP] Word Embeddings - Basics (0) | 2022.04.25 |
| [자연어] BERT 모델, 찍먹해보자. (0) | 2021.09.06 |
| [자연어] 트위터 문자 분류 문제를 통한 자연어 처리 실습(1) (0) | 2021.09.01 |

