ELMo가 나오게 된 배경은?
Glove나 Word2Vec의 경우는 단어간의 위치나 동시 발생 빈도를 고려하여 임베딩을 해왔다. 이렇게 하면, 하나의 토큰에는 하나의 임베딩 벡터가 부여된다. 하지만 문맥을 잘 반영하기 위해서는 "동음이의어"에 대해서도 잘 고려해야 할 것이다. 현재까지의 방법론으로는 "동음이의어"에도 같은 임베딩 벡터를 출력하게 된다.
ELMo의 구체적인 절차
ELMo는 pre-trained된 모델로, 우선 전체 문장을 활용하여 학습한다.
또한, 이미 학습된 양방향 LSTM 을 이용하여, 각 단어의 임베딩 벡터를 생성한다.

문장을 넣으면, 문장의 단어별로 임베딩 벡터를 뱉어주는 구조가 된다.
그러면 엘모가 어떻게 양방향 LSTM을 쓰고 있는지 확인해보자.
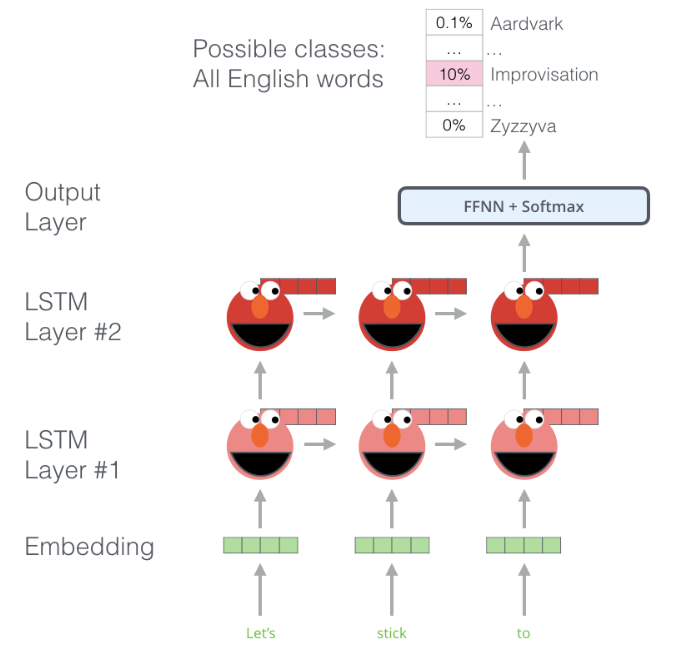
기본적으로, ELMo는 두 개의 LSTM 층을 통과 후, 최종 output을 내는 구조로 되어 있다. 그런데, ELMo는 앞에서 언급한 것처럼 양방향 구조를 가지고 있다. 즉, 역방향 LSTM도 같이 활용한다.
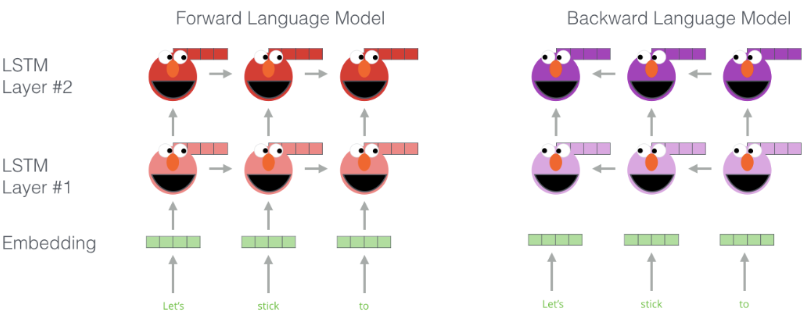
구체적인 임베딩 과정
(1) 순방향 모델과 역방향 모델의 임베딩 층, 2개의 은닉층을 연결한다.
(2) 임베딩층, 첫번째 은닉층, 두번째 은닉층에 각각 가중치를 곱한다.
(3) 세 벡터를 모두 더한다.

'Archive > 자연어처리' 카테고리의 다른 글
| [NLP] FastText란? (0) | 2022.04.30 |
|---|---|
| [NLP] N-gram, Word2Vec, Glove의 간단 개요. (0) | 2022.04.27 |
| [NLP] Word Embeddings - Basics (0) | 2022.04.25 |
| [자연어] BERT 모델, 찍먹해보자. (0) | 2021.09.06 |
| [자연어] 트위터 문자 분류 문제를 통한 자연어 처리 실습(1) (0) | 2021.09.01 |

