* 풀잎스쿨 7주차 대비.
참고자료
[1] https://www.youtube.com/watch?v=0lgWzluKq1k
[2] https://wikidocs.net/24996
seq2seq란?
seq2seq는 encoder와 decoder로 구성되어있음. 즉 정보를 압축하고, 이를 어떻게 표현할지에 대해 표현하는 모델

encoder : 입력 문장를 순차적으로 받아서 하나의 벡터로 (context vector) 만들기
decoder : context vector를 바탕으로 해석, 한 개의 단어씩 순차적으로 뱉는다. (softmax 활용 최종 출력 단어 결정)
* encoder와 decoder 각각은 RNN/LSTM으로 구성됨. (물론 성능 문제로 실제로는 LSTM / GRU로 구성)
* encoder의 마지막 Hidden state를 decoder로 넘겨준다.
단점)
- RNN 기반을 기본적으로 사용하기에, vanishing gradient 문제가 발생한다.
- 하나의 고정된 크기에 모든 정보를 압축하려고 했기에, 정보 손실 또한 발생한다.
=> 길이가 긴 문장일수록 seq2seq를 사용해서는 번역의 품질이 떨어질 것이다. -> attention 도입!
Attention이란?
현재의 output이 무엇을 집중해야 하는지 가중치를 추가로 부여한다. 다시 말해, decoder에서 출력 단어를 예측하는 매 시점마다, 인코더에서의 전체 입력 문장을 다시 한 번 참고한다. 이 때, 연관 있는 단어 부분을 더 집중해서 보고 싶을 것인데, 이를 반영하는 방법이 attention.

- Q : t 시점의 decoder의 은닉 상태
- K : 모든 시점의 encoder의 은닉 상태
- V : 모든 시점의 encoder의 은닉 상태
* Attention의 구조
- Bahadanau attention : attnetion score 자체를 학습,
- Luong attention : 현재의 hidden state와 과거의 hidden state의 유사도를 학습.
* Attention + Seq2Seq
- Encoder는 마지막 hidden state가 아닌, 전체 hidden state를 decoder로 넘긴다.
- Decoder는 output을 수행하기 전, 추가적인 작업을 진행함
* hidden state 각각에 점수를 부여, softmax score를 곱해서 계산한다.
* attention의 자세한 과정 (dot product attention)
Step 1. attention score 구하기

decoder의 은닉 상태와, encoder의 은닉 상태를 내적하여 attention score 계산.
즉 encoder의 모든 은닉 상태와, decoder의 은닉 상태의 유사도를 계산하여 스코어를 매김.
step2. attention score에 softmax 적용 -> encoder의 단어별로 가중치를 얻게 됨
step3. 각 encoder의 은닉 상태와 attention 가중치를 곱하고, 모두 더해서 attention value를 계산
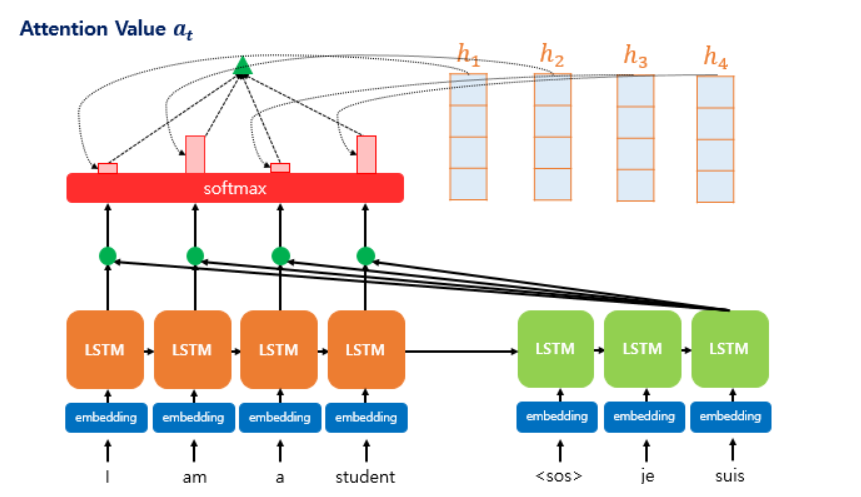
step 4. attention value와 decoder의 hidden state의 concatenate. -> 출력층 계산.
'Archive > TIL' 카테고리의 다른 글
| [TIL] 0704 아침스터디 / VIF, LDA (0) | 2022.07.04 |
|---|---|
| [TIL] Transformer 간단정리. (0) | 2022.06.08 |
| [TIL] LSTM vs GRU 간단하게 정리. (0) | 2022.05.19 |
| [TIL] LTV란?, LTV의 예측 (0) | 2022.05.07 |
| [NLP] Syntax Analysis / Language Model. (0) | 2022.05.03 |


