이론편 : https://taksw222.tistory.com/231
Code : https://github.com/swtaktak/TIL_new/blob/main/data_analyst_practice/240119%20RFM.ipynb
Data출처 : https://www.kaggle.com/datasets/thedevastator/online-retail-transaction-data
지난번 이론편에 이어 이번엔은 RFM 분석을 한번 진행해보겠습니다. 제가 직접 한번 해보겠습니다.
Data 살펴보기
이번 분석 연습도 Kaggle의 데이터로 진행됩니다.

데이터의 첫 10줄을 살펴보면 다음과 같습니다. 몇몇 변수들에 대해 살펴보겠습니다.
InvoiceNo : 송장 번호입니다. 즉 한 번의 구매 단위입니다. 보통 쇼핑몰에서 물건을 1개 사고 또 나갔다 또 사고 그렇게 하진 않겠죠. 장바구니에 쭉 담고 원하는 선물들을 한번에 구매할 것입니다. 그 기준의 단위입니다.
Description : 상품의 상세 내용입니다만, 이것만 봐서는 위의 쇼핑몰은 구체적인 상품군을 확인하긴 어렵습니다. 다양한 것을 판매하는 종합 쇼핑몰로 추정이 되기에 이것만으로 인사이트를 얻기는 어렵습니다.
Quantity, UnitPrice : 상품 구매 수량과 개당 가격입니다. $ 기준일 것이라 추정됩니다.
Country : 국가입니다. 특정 하나의 국가에 대해서 분석할 때 사용할 수 있겠습니다. 이번 분석에서는 국가 데이터는 고려하지 않고 전체 회원을 대상으로 분류해보는 작업으로 진행하고자 합니다.
전처리 및 RFM 준비 과정
* 이번에는 전처리 과정이 특이합니다. 정신 바짝 차리고 따라오셔야 합니다.
데이터를 받았으니, 전처리를 진행해야겠죠. 깔끔하다는 보장이 없으니 결측치가 있다면 처리해야 할 것입니다.

아, 결측치가 존재합니다. 게다가 결측치는 CustomerID에 있습니다. 해당 로그데이터들은 누가 거래했는지를 알 수 없습니다. RFM 분석에 쓰기에는 적합하지 않겠기에, 제거하겠습니다. 해당 결측치를 제거하면 자연스럽게 상품의 Description 결측치도 제거됩니다. 물론 RFM 분석에서 세부 상품 내용은 특정 상품군을 보는 것이 아닌 이상 의미는 없겠습니다.
이제 RFM 분석을 위해 각 요소를 만들어 줄 것입니다. 여기서 Frequency 영역을 다양하게 생각할 수 있습니다.
Frequency를 다양한 방법으로 생각할 수 있는 이유는 다음과 같습니다.
- 마켓인 상품에 따라서는 특정 상품을 반복적으로 구매하는 것이 유도될 수 있습니다.
EX) 구독권 형태의 상품들이나 주기적으로 사야 하는 상품들
- 도매 업체에서 주로 사용하는 플랫폼일 경우 구매하는 상품의 양도 중요할 것입니다.
- 고급화된 상품을 판매하는 곳일 경우 횟수 자체보다는 한 건의 구매금액 등도 중요할 것입니다.
- 기타 도메인에 따른 다양한 상황을 생각해 볼 수 있습니다. 이는 도메인에 따라 달라질 것입니다.
즉, 마켓의 상황에 따라서 어떤 Frequency를 도입할지에 대해 고려해야 합니다.
이번 분석에서는 우리는 마켓에 대한 정보를 모릅니다. 따라서 다양한 경우를 볼 것입니다.
따라서, RFM 분석에 들어갈 요소는 다음과 같이 뽑아내겠습니다.
- 가장 마지막 구매일 : 최종 결제일을 알 수 있다. (R)
- 총 구매 종류 수 : 전체적으로 산 상품의 종류 수(중복도 세서)를 알 수 있다. (F)
- 총 구매 상품 개수 : 개당으로 합쳐서 총 몇 개의 상품을 샀는지도 참고할 수 있다. (F)
- 총 Invoice 개수 : 몇 묶음(몇 번의 "주문")을 샀는지 알 수 있다. (F)
- 총 가격합 : 그래서 Quantity * Price의 합으로 몇달러의 매출을 냈는지 알 수 있다. (M)
이를 일단 쿼리를 작성하면 쉽게 뽑겠죠?
SELECT
CustomerID,
count(*),
count(distinct InvoiceNo),
sum(Quantity),
sum(Quantity * UnitPrice),
max(substr(InvoiceDate, 1, 9))
FROM customer_retail
GROUP BY CustomerID
LIMIT 5데이터가 의도대로 뽑혔는지, 다른 노이즈 등은 없는지 체크를 위해 5줄만 뽑아보았는데...

첫번째 데이터가 상당히 이상합니다. 구매 건수가 2건인데, 어떻게 수량과 금액이 0일까요..?
원래 데이터에서 이를 확인해봅시다.
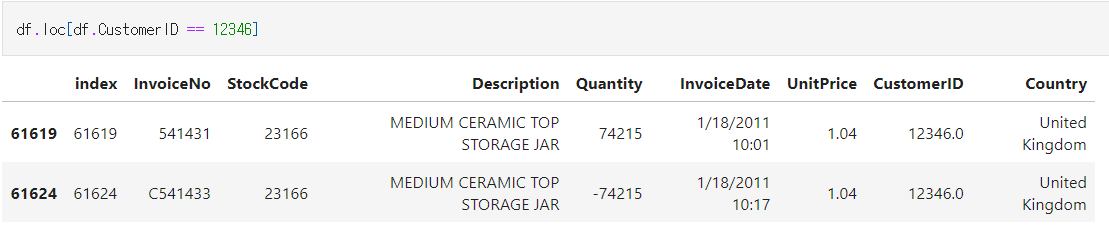
동일한 상품에서 위와 같은 로그가 나왔다는 것은 환불 건입니다. 환불 건은 유효한 거래가 아닐 것이기에, 제외해야 합니다. 또한 이렇게 생각하면 다른 이유로 음의 값을 가진 quantity가 나올 수 있고 이를 제외해야 합니다.
문제는 깔끔하게 InvoiceNo에 규칙성이 있으면 좋지만 아쉽게도 그러지는 않습니다. 또 세션관련 정보도 존재하지 않아 정확하게 딱 환불을 완벽하게 계산하기는 어려울 것 같습니다. (부분환불도 존재할 수 있으니까요)
여기서는 그래도 최대한 전체 환불은 제외해보는 방향으로 전처리를 시도해보기로 합니다. 데이터프레임에서 index를 지우지 않은 것은 이러한 사태가 나올 수 있기에, 열을 구분하기 위한 지표로 남겨둔 것입니다.
del_indx = []
for i in range(len(df)):
cur_row = df.loc[i]
if cur_row['Quantity'] < 0:
del_indx.append(cur_row['index'])
cur_des = cur_row['Description']
cur_quan = cur_row['Quantity'] * -1
cur_id = cur_row['CustomerID']
del_df = df.loc[(df.Description == cur_des) & (df.Quantity == cur_quan) & (df.CustomerID == cur_id)]
if len(del_df) > 0:
cur_del_idx = list(del_df['index'])[0]
del_indx.append(cur_del_idx)양이 0일 때, 동일한 양을 음수로 가지며, 동일한 상품, 동일한 양일 경우 전체환불이라 판단하고 아닐 경우는 다른 예외로 판단하여 모두 지우는 코드입니다. 그 해당 인덱스를 가진 줄을 모두 찾아 저장합니다. 약 12,000개의 데이터가 존재하여 제외 대상입니다.
문제는 전체 로그가 약 40만개이고, 지울 인덱스 번호에 해당되는지 일반적인 탐색으로는 말도 안되는 시간이 걸립니다. 실제로 특정 원소가 리스트에 있나 없나 판단할때는 리스트의 앞부터 탐색하는 것으로 되어있습니다. 이 방법으로 하면 답도 없이 시간이 오래 걸려, 지울 인덱스에 해당되는지 아닌지 이진탐색을 활용하여 빠르게 찾아서 처리합시다.(사실 이 이진탐색 부분이 이번 전처리의 특이ㅈ.... 읍읍)
# 지워야할 index 체크가 너무 많아서 어렵다. 이진탐색으로 빠르게 끝내게 만들어주자.
# 안그러면 사십만 * 만개이어서 얼마나 걸릴지 모른다.
def binary_check_indx(x):
start = 0
end = len(del_indx) - 1
while start <= end:
mid = (start + end) // 2
# 그 값일 경우 제외해야 한다.
if x == del_indx[mid]:
return False
# 찾아야할 인덱스가 적을 경우
elif del_indx[mid] > x:
end = mid - 1
else:
start = mid + 1
return True
df_condi = df['index'].apply(lambda x : binary_check_indx(x))
df = df.loc[df_condi]이렇게 하면 전체 환불대상 + 환불 열들 + 기타 이유로 음의 값을 가진 양의 주문량을 가진 로그가 제외됩니다.
완벽한 전처리는 아니지만 추가적인 데이터를 확인하긴 어려우므로 다음 분석을 진행합니다. 추가로 날짜 데이터도 'YYYY-MM-DD' 형태로 형식을 통일하여 진행하였습니다.
이후 쿼리를 다시 돌려보면, 다음 table을 얻게 됩니다.
변수명을 한번 정리하겠습니다.
id : 고객의 unique한 id
cnt_prod : 총 구매 상품의 가짓수(중복 구매도 모두 셌습니다)
cnt_pay : 총 구매 횟수
cnt_quant : 개별 상품의 개수를 합친 총 구매 합산 수량
total_rev : 구매 금액
last_buy_date : 가장 최근의 결제일

RFM 등급 매기기
이제 등급을 매겨보겠습니다. 등급을 매기기 위해 날짜를 제외한 나머지 수치형 변수들의 값을 요약해서 봅시다.

딱봐도 75%와 max의 차이만 봐도, 이상치가 존재합니다. 시각화로 확인해보겠습니다.
어느정도 반복적인 작업이기에, 여기서는 cnt_prod에 대해서만 살펴봅니다.

큰 값으로 이상치가 대폭 존재합니다. 즉, 극상위층에 대해서 별도 구분을 해두면 이상치를 고려하는데에도 적합해 보입니다. 마지막 구매 날짜를 제외한 나머지 변수들도 유사한 분포를 가집니다.
즉 Frequency와 Monetary에 대해서는 "상대평가"로 등급을 매기는 것이 적합해 보입니다.
이럴 때 가장 고려하기 좋은 방법은 "분위수"를 활용하는 것입니다. 다시 말해,
- D : 하위 25%
- C : 25~50%
- B : 50~75%
- A : 75~99%
- S : 상위 1%
이런 방법으로 등급을 나누는 것입니다. 실제로 매출의 경우는 상위 N%의 유저가 매출 기여도가 높게 나올것이기에, 극상위층을 별도로 묶어서 최상위 등급으로 고려해보는 것도 유의미할 것입니다. 정확한 %를 더 찾아볼 수 있겠으나 이는 실제 장기 기간의 매출 데이터 등을 바탕으로 결정해야 할 것입니다. 여기서는 배경지식 없이 처음 받는 데이터로 RFM을 하는 것이라 임의로 1%로 지정하였습니다.
np.percentile을 활용하면 100분위수를 뱉어주므로, 쉽게 등급 배치가 가능합니다.
def get_grade_prod(x, q):
if x < q[0]: return 'D'
elif x < q[1]: return 'C'
elif x < q[2]: return 'B'
elif x < q[3] : return 'A'
else: return 'S'
q_prod = np.percentile(customer_df['cnt_prod'], [25, 50, 75, 99], interpolation='higher')
q_pay = np.percentile(customer_df['cnt_pay'], [25, 50, 75, 99], interpolation='higher')
q_quant = np.percentile(customer_df['cnt_quant'], [25, 50, 75, 99], interpolation='higher')
q_rev = np.percentile(customer_df['total_rev'], [25, 50, 75, 99], interpolation='higher')
customer_df['cnt_prod_grade'] = customer_df.cnt_prod.apply(lambda x : get_grade_prod(x, q_prod))
customer_df['cnt_pay_grade'] = customer_df.cnt_pay.apply(lambda x : get_grade_prod(x, q_pay))
customer_df['cnt_quant_grade'] = customer_df.cnt_quant.apply(lambda x : get_grade_prod(x, q_quant))
customer_df['total_rev_grade'] = customer_df.total_rev.apply(lambda x : get_grade_prod(x, q_rev))이제 구매 날짜에 대한 등급도 매겨봅시다. 이를 위해서는 유저 풀 내 최초 구매일과 최종 구매일을 알아야 합니다.

대략 1년 정도의 기간입니다. 이 기간 역시 특정 산업군에 따라서 최종 구매 시점의 템포가 길어질 수도 있는데, 데이터에서는 다양한 상품을 판매하고 있었기에 등급이 높은 사용자를 조금 빡센(?) 기준으로 잡겠습니다.
- D : 나머지
- C : 180일 전까지
- B : 90일 전까지
- A : 30일 전까지
- S : 7일 전까지
로 등급을 배정하였습니다.
이렇게 등급을 하여 최종 등급배치 결과를 얻을 수 있습니다.

RFM 결과의 활용
문제는 이 결과에 대한 활용입니다. 활용방안을 다양하게 생각할 수 있습니다.
- 앞으로 충성도가 높을 고객은 누구인가?
- 충성도가 높았는데 떠나버린 고객은 누구인가?
- 매출 기여도가 높은 고객은 어떤 집단인가?
등등...
많은 문제를 고려할 수 있습니다. 산업군에 따라 Frequency로 만든 지표 중 여러가지를 도입할 수 있고, 가중치를 달리하여 매출 기여도를 확인할 수 있을 것입니다. 이에 대해서는 많은 실험이 필요할 것입니다.
문제 상황에 따라 이를 해결할 수 있을것입니다. 하나의 작은 예시로 이를 보겠습니다.
문제 / 현재 신규 유저의 유입은 증가하나 지속적으로 Mall의 매출이 감소하고 있는 상황이다.이에 대한 문제를 해결하기 위해 적당한 유저들에게 프로모션을 진행할려 하는데, 어떤 유저들을 할지 선택해주세요.
해결 /
(1) 매출 등급이 S나 A인 유저 중 최근 구매 이력이 3개월이 초과된 (C, D) 유저들을 확인한다.
(2) 최근에 구매 이력이 있는 유저 중(S등급) 앞으로도 구매 금액 등이 높을 것이라 기대되는 유저를 선정한다.
각 case별로 알맞은 캠페인, 프로모션등을 협의하여 진행하고 실제로 매출이 회복되었는지, 회복되었지 않았다면 다른 지표로 무엇을 고민해야 할지 등을 지속적으로 논의할 수 있을 것이다.
추가 발전 방향
이렇게 나눈 집단별로 유저의 동태를 파악할 수 있을것입니다.
Ex) 각 집단별로 구매 리텐션 등은 어떤지, 특정 집단의 리텐션이 하락하는지 등등
주요 집단별로 핵심 지표등을 모니터링하며 변화를 관찰하는 쪽으로 이후 분석을 발전 시킬 수 있을 것입니다.
이를 위해서는 활동 로그 데이터 등 더 많은 데이터와 결합하여 문제를 설정하면 될 것이라 기대됩니다.
+ 그룹을 나누는 기준은 여기서는 어떤 배경지식이 없기에 통계적인 부분을 활용하였지만, 실제로는 도메인이 중요할 것입니다. 현실의 상품들은 시기성이나 계절성이 있기 마련입니다.
가령 예를들어, 의류매장일 경우 봄/여름/가을/겨울 사계절의 흐름이므로 3개월 주기로 옷을 적당히 리필(?) 한다고 가정하면 6개월 정도만 미구매여도 최근 방문 지수를 D 줄수도 있습니다. 개수도 이에 따라 자유롭게 조절 가능하겠고요.
+ 추가로 받았던 피드백은, RFM 분석으로 무언가를 얻을려면 "동기간 대비 비교"가 하나의 방법이 될 수 있다는 점이었습니다. 잘 생각해보면 대부분의 현실에서 무언가를 살 수 있다면 특정 하나의 상품 생명주기가 존재할 것인데, 그 주기를 비교하여 매출이 처지는 상황을 문제라고 볼 수 있을 것입니다. 그 주기를 정확히 파악하는 것 또한 중요할 것입니다. 역시 도메인이 분석의 생명인 것 같습니다.
'Archive > 데이터 분석 관련' 카테고리의 다른 글
| [Data] 업리프트 모델링이란? - 개념편 (0) | 2024.01.29 |
|---|---|
| [Data] 이탈분석 - 생존분석 개괄편 (1) | 2024.01.24 |
| [Data] RFM 분석이란? (이론편) (0) | 2024.01.17 |
| [Data] A/B Test 사용해보기 : Cookie-Cats (0) | 2024.01.16 |
| [Data] Retention (2) | 2024.01.15 |


